学者综合症:模式识别就等同于智能吗?
产品展示
发布日期:2024-11-18 15:42 点击次数:187
神译局是36氪旗下编译团队,关注科技、商业、职场、生活等领域,重点介绍国外的新技术、新观点、新风向。
编者按:OpenAI GPT-4o1的发布让大家纷纷宣称推理将是人工智能发展的下一步,说思维链等技术会提高人工智能的推理技能。一些结果似乎证明了人工智能的思维能力,但且慢,那些结果真的能说明人工智能具备了这种能力吗?文章来自编译。
我几乎从未见过懂推理的数学家。
——柏拉图
推理得出一个结论,但并不能使结论确定,除非心灵通过经验的道路发现它。
——罗杰·培根
大语言模型 (LLM) 表现出了卓越的能力,尤其是在自然语言处理中的经典任务(例如问答)方面。令人惊讶的是,它们在需要推理的复杂任务(例如编码和数学)中表现出了进步。这些能力长期以来被认为是人类独有的。因此,声称 LLM 可以解决需要推理的任务引发了激烈的争论。
大语言模型 (LLM) 真的会推理吗?还是说只是复杂的模式匹配器?
推理能力对人工智能系统与人类互动并用到关键任务上至关重要。推理要求逻辑推理、进行推断、解决问题,并能根据可用信息做出决策。在科学发现、医疗保健、金融和教育等领域能起到真正帮助作用的模型也需要类似的技能。
新模型的发布让这场争论变得更加激烈。随着 OpenAI GPT-4o1 的发布,大家对用 CoT (思维链)训练模型来提高推理能力产生了浓厚兴趣。CoT 训练出来的 LLM 的成果,已经让部分公司站出来说,如今的LLM 已经具备了推理能力,AGI (通用人工智能)越来越近了。
所以今天我们就来大辩一场吧:一方面有公司和研究人员声称模型具备了推理能力,另一方面,也有人把 LLM 说成是随机的鹦鹉。
本文将重点回答以下问题:
推理是什么意思?
LLM 是否具有推理能力,还是只是学舌鹦鹉?
我们究竟有没有在用对的方式来衡量推理?
推理的定义?
推理是根据现有信息、逻辑和分析得出结论或做出决策的基本认知过程。按照亚里士多德的说法,推理可以分为两种:
演绎推理。基于观察的概括。
归纳推理。从一般原则得出具体结论。
长期以来,人们认为只有人类才具有推理能力。如今,人们发现灵长类动物、章鱼和鸟类也具有基本的推理能力,例如做出决定或解决问题。
一般来说,推理应该是解决复杂问题或做出决策的过程。解决复杂问题需要识别问题,将其分解为子问题,寻找模式,然后选择最佳解决方案。决策同样需要识别问题和模式,并在选择最佳解决方案之前评估替代方案。
这些定义的问题在于不完全清晰。而且,根据这些定义,LLM 也可以被认为具备推理能力了。
LLM 能推理吗?
在衡量推理能力的基准测试(如 GLUE、 SuperGLUE和Hellaswag )中,LLM 的表现其实是优于人类的。在某些人看来,这意味着 LLM 可以进行推理并得出合乎逻辑的结论。
这些新的推理能力主要是因为两个因素:
大语言模型在所有针对推理的基准测试中都展现出推理能力
随着参数、标记数量以及算力预算的增加,涌现出新的属性。
用CoT等技术可以让模型发挥潜力。
因此,如果我们想下结论说大语言模型缺乏推理能力,就必须挑战这些说法。
大语言模型的推理基准测试成绩惊人
当然,当有人声称大语言模型不具备推理能力时,AGI 的支持者会回应说“看看推理基准测试的结果吧。”用鸭子测试的话来说:如果它能能像人类一样解决问题,像人类一样做决定,并能赢得推理基准测试的话,那它可能就能像人类一样推理。
有些作者对这个结论提出了质疑[1]。虽然表面上看,模型似乎能进行复杂推理,但从更详细角度来看,它们依赖的是概率模式匹配,而不是形式推理。
强烈的Token(标记)偏差表明模型依赖的是输入的表面模式,但其实它并不理解底层的推理任务。
换句话说,这些脆弱的表现表明,当LLM遇到与训练期间见到的模式不同的新示例时,它们无法泛化。因此,更改示例中的标记会导致逻辑错误(因为模型没法再将该示例映射到训练所见到的内容)。因此,模型对测试呈现的示例非常敏感,且较为脆弱(这可能解释了为什么它们有时候推理能力表现出色,而有时候却错得离谱)。
这种脆弱性在示例标记发生扰动时尤为明显,导致LLM无法解决问题(因此其“推理”依赖于这些标记,并将其映射到训练集所见的内容)。示例在训练数据的出现频率与测试性能之间的相关性验证了这一点。
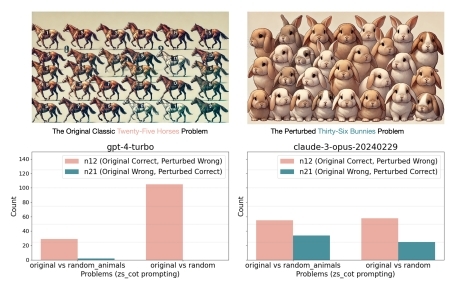
“图论经典的‘二十五匹马’问题。上面两张图是GPT-4o生成的,右图把马变成了兔子,用来说明问题的底层逻辑并不受影响。下方两图分别是GPT-4与Claude的实验结果,就因为动物名称和数量发生扰动,AI的表现就显著下降了。”
这种现象被称为“提示词敏感性”(对语义等效的提示词产生不同的响应)。这表明模型对与训练中见到的文本更为相似的提示词的响应更好。
它们对噪音也非常敏感。事实上,LLM容易受到不相关背景的干扰,导致推理性能下降。此外,即便使用了那些旨在提高推理的提示词技术,噪声效应也无法消除。这表明用噪音干扰映射会影响模型找到这些模式的能力。
智能具有涌现属性
在很多人看来,智能具有涌现属性。生物系统自然趋向于变得更加复杂并获取新能力,否则它们将被进化压力所淘汰。进化过程导致生物变得越来越智能或更加专门化。智力因此在这种压力下进化。当然它需要资源,因此大脑必须增长到临界水平来支撑智力的演进。在某些人看来,模式训练的损失函数起到了一种进化压力的作用。所以一旦模型拥有足够的“神经元”,它们就可以发展出推理技能(用技术术语来说,推理属性会随着规模的扩大而涌现)。
如前所述,推理能力的提高归因于规模的扩大(无论是参数还是训练标记)。然而,对于一些作者来说,推理能力是一种突现属性,需要一定的参数阈值才能出现。然而,后来的研究表明,大语言模型中的突现属性可能是一种测量误差,因此,整个理论都与推理的突发性有关 [3, 13]。
如前所述,这种推理能力提高可归因为规模扩大(不管是参数还是训练标记的数量)。然而,对一些作者而言,推理能力具有涌现性,只有在参数达到一定阈值时才能出现。然而,后来的研究表明,LLM的涌现性可能就是一种测量误差,因此整个理论均与推理的涌现性相关。
思维链(CoT)并非万能解决方案
另一部分研究者认为,LLM具备推理能力,但需要“解锁”出来。而思维链(CoT)提示词通过中间推理步骤帮助模型挖掘潜力,从而引导其在算术问题中得出正确答案。但几周前,有一篇文章对CoT的实际效果提出了质疑:
“在MMLU基准测试中,CoT带来的性能提升当中有多达95%是由于问题里面包含有‘=’符号的题目或生成的答案。对于非数学问题,我们未发现任何表明CoT有帮助的特征。”
那么,CoT顶多能帮助解决数学问题,但显然并未“解锁”LLM的推理潜力。尽管如此,CoT仍被视为一种灵丹妙药,甚至被认为是新一代LLM推理能力的基础。
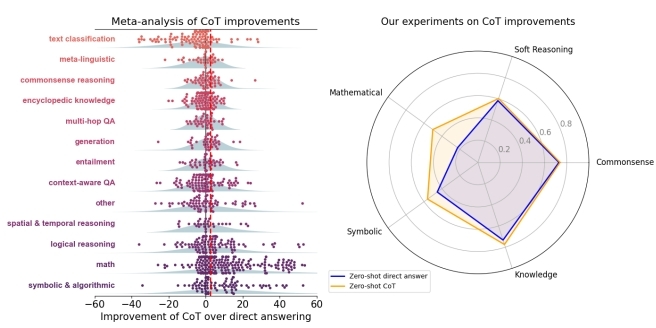
在两组结果里,始终表明CoT有显著提升的地方是数学和其他符号推理(红色虚线表示实验中CoT的平均提升水平)。
LLM 真的具备数学推理能力吗?
尽管数学推理似乎是LLM的强项,但一些研究表明LLM仅仅能识别模式。换句话说,LLM只是在寻找模式,但并没有真正理解符号。
根据一些作者的观点,LLM无法进行数学形式推理,因为它们不能制定计划(计划定义为一系列动作步骤,通过执行这些步骤将智能体从初始状态带入期望的目标状态)。因此,在没有计划的情况下,模型无法解决问题,只能映射训练中见到的模式。甚至在某些情况下,用户可能无意间引导了LLM得出解决方案:
“聪明的汉斯效应”指的是LLM只是在生成猜测,而这个过程中知道解决方案对错的人才是引导LLM的关键——即便他们并未刻意如此。模型的准确与否其实取决于人的参与。
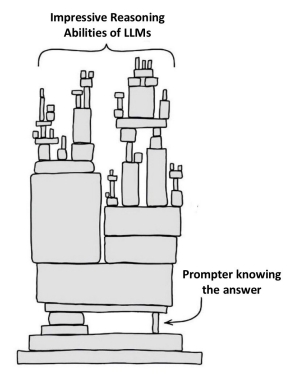
“所宣称的LLM的推理能力,有时候是由于人类在潜意识当中不断给出的,迭代性的,有帮助作用的提示”
总结,到目前为止,LLM 推理的支持者认为,我们今天观察到这种行为有几个原因。我们收集了一些证据,有几项研究表明这些说法与这些说法相矛盾。
尽管这些研究表明LLM缺乏真正的推理能力,但它们在基准测试中表现出色,甚至通过了对人类而言也比较复杂的测试。因此,我们提出的证据似乎更多的是 LLM 解决数学和复杂问题能力的理论证据,而不是实验证据。
是人类对被LLM击败而感到不悦?还是出了什么问题?
抓住抄袭的学生
当然了,听到有人说LLM的表现跟博士生一样,肯定会让人很恼火:
“O1-preview模型通过花费更多时间进行思考和完善其回答来处理复杂任务,这跟人类处理复杂问题的方式类似。在测试中,这种方法使得模型在物理、化学和生物学等领域的表现接近博士生水平。”
抛开不悦不谈,问题在于我们如何测量这些模型的能力。我们可能没有采用正确的方式来衡量其推理能力,是时候考虑新的测量体系了。
这些模型通常用跟GSM8K数据集(小学数学8K数据集)一样的基准测试来测试,这些基准测试提供了复杂的算术问题,但存在数据泄露风险(考虑到训练LLM使用的数十亿个Token,模型可能在训练时见过答案)。此外,这种测试只根据固定的问题集提供单一指标,让我们难以准确评估LLM的推理能力(有趣的是,LLM有时候回答是正确的,但推理过程却明显是错误的)。最后,该数据集是静态的,不允许更改测试条件。
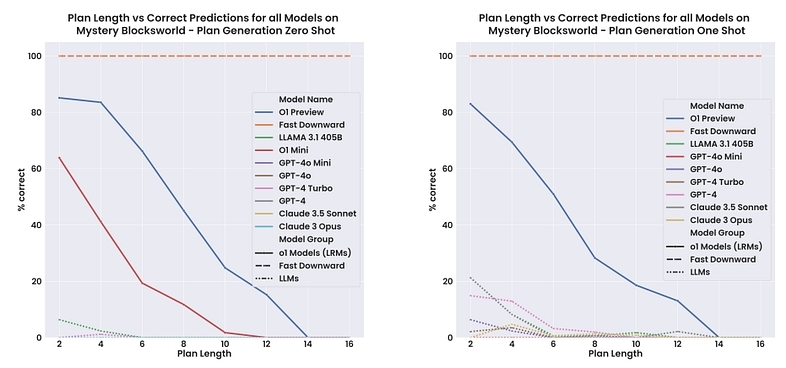
为此,他们提出了一个新基准数据集GSM-Symbolic ,这个数据集使用符号模板来生成不同的问题。这种数据集还支持调整问题难度并进行更细化的控制。如果LLM具备推理能力,它应当能够轻松解决这些问题,但如果不懂泛化的话就会输得很惨。

GSM-Symbolic 模板创建过程示意图。
在测试最先进的 LLM 时,作者们找不到语言模型具备形式推理的任何证据。这些模型不够稳健,当数值发生变化时,其性能会大下降,而且随着问题复杂性的增加,其能力会急剧退化。
举个例子,如果给问题添加看似相关的陈述(实际上与推理和结论无关),模型就很容易受到这些信息干扰而出错。研究指出,模型其实并不理解数学概念,只是在试图将这些陈述转化为运算步骤。研究作者提出,这可能是因为训练数据集中包含了类似需要转化为数学运算的示例。
比方说,模型经常会不管上下爱问语境如何就将关于“折扣”的陈述直接解读为“乘法”操作。这不禁让人质疑:这些模型到底懂不懂数学概念。

这再次表明,即便在面对只是背景噪音的无关信息时,模型也会试图在其中寻找模式。当噪音增加,使得寻找模式(或一致地映射从而得出解决方案)更困难时,模型的表现就会显著下降。这一点同样适用于通过思维链(如ChatGPT4-o1)训练的LLM。这进一步表明CoT的其实并没有改善推理技能。
结语
本文探讨了一个重大争议:LLM是否具备推理能力?或至少具备某种形式的推理能力?
我们展示的研究更倾向于认为LLM是复杂的模式匹配机器。总结而言,这些研究得出的观点如下:
LLM经过了大量标记的训练,因此主要基准测试可能存在数据污染风险。即便模型未见过某个数学问题,它也可能见过许多类似示例。
由于其庞大的知识储备和天生的模式发现能力(源自注意力机制和上下文学习),LLM能够解决大部分问题。
它们对问题变体缺乏鲁棒性,存在标记偏差,且对噪音敏感,这些强烈表明LLM并不具备正式推理能力。
新研究表明,即便使用高级提示词技术,模型依然对噪音和无关(或误导性)信息敏感。
模型具备模式匹配能力,但似乎并未真正理解问题解决的数学概念。
这些结果并非质疑LLM的实用性,而是质疑认为LLM具备推理能力的假设。LLM可以视为拥有惊人记忆力,但缺乏推理能力(或许是至今最复杂的“机械鹦鹉”) 的机器。这并没有贬低这项技术成就的意义,而是赞叹人类创造力的奇迹。未来可能需要进一步研究来更好地解释LLM的能力,并探索具备推理能力的新模型架构。
译者:boxi。